
Instructions - Register you email address to receive the login information.
- Choose
only one of the two datasets (the complete dataset contains 100
additional series plus the 11 series of the reduced set. Those
forecasting the complete set will automatically be evaluated on both
data sets):
- a reduced dataset with 11
time series, or
- the complete dataset with 111 time series
- Download the data.
- Develop a single methodology to use on all time series - ideally in software code or rigorously though documented steps & tests conducted by a human expert
(see below & FAQ for explanation).
- Document the methodology in a brief summary of
2 to 6 pages IEEE format (template will be provided later).
- Forecast the last 18 observations for each of the 11 or 111 time series
(for the in-sample data please provide the 1-step ahead forecasts, as
there is no room to provide 18-step ahead forecasts for each time origin
of the training data. This data will be used to validate goodness of
fit, but will not be used to evaluate and rank the performance of your
submission).
- Record the forecasts in the original data file.
- Rename the file to include your name.
- Submit your predictions
using the information on the website [NN3
submission page ] - deadline May 14, 2007.
- Submit your description of the methodology used to the website
[NN3 submission page ] - deadline May 14,
2007.
In addition, we encourage you to submit to one of the conferences where we will host special sessions. This will allow you to - submit only an abstract & present at the International Symposium on Forecasting, ISF'07 without publication of a paper
- submit a full paper describing your methodology, software, systems and results at one of the other conferences IJCNN'07, DMIN'07 etc.
- submit abstract & paper to two conferences!
- submit to the post-competition publication on "Advances in Neural Forecasting" by Springer
- the most innovative approaches
and best papers will be invited to a special issue of the International
Journal of Forecasting (IJF) by Elsevier.
Please check back here regularly for information on submission deadlines & dates for theses conferences. General Instructions - Submissions are restricted to one entrance per competitor.
- The competitors must certify upon submission that they didn’t try to retrieve the original data.
- As this is predominantly an academic competition, all advertising based upon or referencing the results or participation in this competition requires prior written consent from the organisers.
Experimental Design The competition design and dataset adhere to previously identified requirements to derive valid and reliable results. - Evaluation on multiple time series, using 11 and 111 monthly time series
- Representative time series structure for Industry containing short & long, noise time series
- No domain knowledge, no user intervention in the forecasting methodology
- Ex ante (out-of-sample) evaluation
- Single time series origin (1-fold cross validation) in order to limit effort in computation & comparisons
- Fixed time horizon of 18 months into the future t+1, t+2, ..., t+18
- Evaluation using multiple, unbiased error measures
- Evaluation of "novel" methods against established statistical methods & software packages as benchmarks
- Evaluation of "novel" methods against standard Neural Networks software packages
- Testing of conditions under which NN & statistical methods perform well (using multiple working hypothesis)
Datasets Two datasets are provided, which may be found [here]. Methods The competition is open to all methods from Computational Intelligence,
listed below. The objective requires a single methodology, that is
implemented across all time series. This does not require you to build a
single neural network with a pre-specified input-, hidden and output-node
structure but allows you to develop a process in which to run tests and
determine a best setup for each time series. Hence you can come up with 111
different network architectures, fuzzy membership functions, mix of ensemble
members etc. for your submission. However, the process should always lead to
selecting the same final model structure as a rigorous process. - Feed forward Neural Networks (MLP etc.)
- Recurrent Neural Networks (TLRNN, ENN, ec.)
- Fuzzy Predictors
- Decision & Regression Trees
- Particle Swarm Optimisation
- Support Vector Regression (SVR)
- Evolutionary & Genetic
Algorithms
- Composite & Hybrid approaches
- Others
These will be evaluated against established statistical forecasting methods - Naïve
- Single, Linear, Seasonal & Dampened Trend Exponential Smoothing
- ARIMA-Methods
Statistical benchmarks will be calculated using the software ForecastPro, one of the leading expert system software packages for automatic forecasting. ForecastPro comparisons are provided by courtesy of Eric Stellwagen. Thank you Eric! We hope to also evaluate a number of additional packages: Autobox (pending), NeuralWorks (pending), Alyuda Forecatser (peding), NeuroDimensions (pending). Evaluation
We assume no particular
decision problem of the underlying forecasting competition and hence assume
symmetric cost of errors. To account for a different number of observations
in the individual data sub-samples of training and test set, and the
different scale between individual series we propose to use a mean
percentage error metric, which is also established best-practice in industry
and in previous competitions. All submissions will be evaluated using the
mean Symmteric Mean Absolute Percent Error (SMAPE) across al time series.
The SMAPE calculates the symmetric absolute error in percent between the
actuals X and the forecast F across all
observations t of the test set of size n for
each time series s with
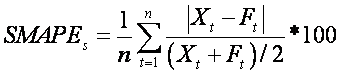
The SMAPE
of each series will then be averaged over all time series in the dataset for
a mean SMAPE. To determine a winner, all submissions will be ranked by mean
SMAPE across all series. However, biases may be introduced in selecting a
“best” method based upon a single metric, particularly in the lack of a true
objective or loss function. Therefore, while our primary means of ranking
forecasting approaches is mean SMAPE, alternative metrics will be used so as
to guarantee the integrity of the presented results. All submitted forecasts
will also be evaluated on a number of additional statistical error measures
in order to analyse sensitivity to different error metrics. Additional
Metrics for reporting purposes include:
-
Average SMAPE (main metric to determine winner)
- Median SMAPE
-
Median absolute percentage error (MdAPE)
- Median relative absolute error (MdRAE)
-
Average Ranking based upon the error measures
- …
Publication & Non-Disclosure of Results We respect the decision of individuals to withhold their name should they feel unsatisfied with their results. Therefore we will ask each & every contestant's permission to publish his name and software package used AFTER he learns his relative rank on the datasets. (However, we reserve the right to indicate the type of method and methodology used, i.e. MLP, SVR etc without the name). |